Quello che state per leggere è un articolo nato dalla collaborazione tra gli studenti di Data Science dell’Università di Milano-Bicocca e noi di Info Data con l’obiettivo di formare gli studenti di data science sull’applicazione dell’analisi dei dati al giornalismo.
Per decenni alla guida del Paese si sono alternate le stesse forze politiche, scambiandosi di tanto in tanto il ruolo grazie a pochi voti. Nelle elezioni politiche di marzo 2018, invece, la “vecchia politica” è crollata lasciando il posto quasi in ugual misura all’astensionismo e alle preferenze per il Movimento 5 Stelle. Il Movimento 5 Stelle cattura nei suoi argomenti e nella sua propaganda il disamore verso la politica e le sue istituzioni. Sin dagli albori quando il Blog di Beppe Grillo lanciò il “V… day” il Movimento si è posizionato come la ribellione alla “casta” ed ai “poteri forti”, spesso denunciati come nemici del popolo e dei cittadini. Per approfondire le ragioni di questo terremoto politico abbiamo provato a analizzare il voto con altri indicatori (seguirà un post dedicato al reddito territoriale). Nessuno finora ha per esempio provato a capire se esista una relazione tra la propensione a barare sulle proprie competenze e quindi la disonestà nei confronti dei sistemi di valutazione e il voto alle politiche.
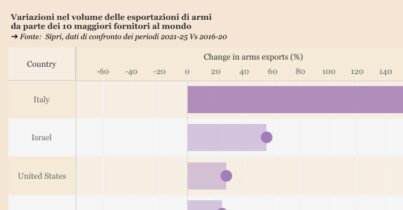
Per analizzare i risultati elettorali nel dettaglio facciamo uso di un grafico ternario in cui la posizione di una provincia è determinata dal rapporto relativo tra i voti delle tre maggiori forze politiche. Le tre forze politiche di Partito Democratico, Lega-Forza Italia e Movimento 5 Stelle sono poste ai vertici e, maggiore la componente di voto per una fazione in una data provincia, più vicino sarà il segno che la rappresenta al vertice di quella fazione.
Il colore dei simboli indica il valore del coefficiente di Cheating INVALSI rispetto alla media nazionale, mentre il simbolo indica se tale valore si pone al di sopra o sotto tale media.
Risulta ovviamente difficile e avventato trarre conclusioni da questi dati, ma è chiaro come contribuiscano a costruire un’immagine delle province interessate caratterizzata da un forte sentimento di alienazione dell’elettore rispetto alle istituzioni. Questo richiama la disaffezione mostrata verso i partiti storici, e può essere collegato al ritardo nello sviluppo economico di cui spesso soffrono questi stessi territori. Chi si sente meno rappresentato dal governo lo abbandona, ma se decide comunque di votare lo fa “per protesta” nella speranza di un cambiamento radicale, che in molte province si è prevalentemente concretizzato in un voto al Movimento 5 Stelle.