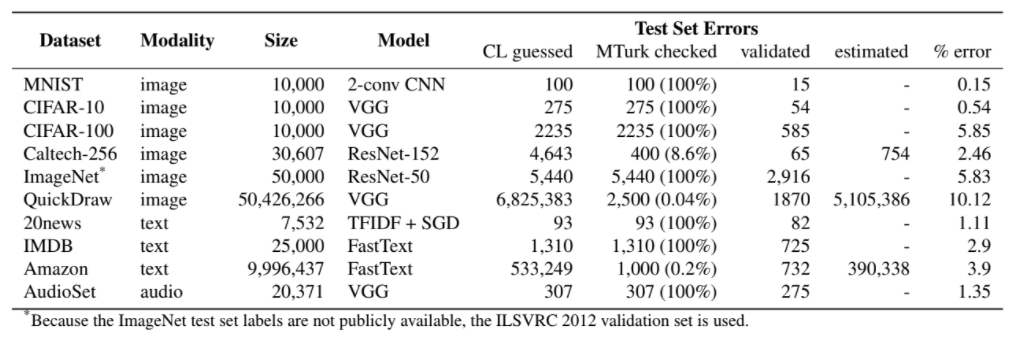
Un team guidato da data scientist del MIT ha esaminato dieci dataset tra i più utilizzati per i test degli algoritmi di apprendimento automatico (machine learning) Hanno scoperto che circa il 3,4% dei dati era impreciso o etichettato in modo errato, il che, hanno concluso, potrebbe causare problemi ai sistemi di intelligenza artificiale che utilizzano questi set di dati. Più nello specifico ai benchmark e quindi ai test che vengono usati per dare un voto alle prestazioni dei sistemi di machine learning. La differenza non è di poco conto perché i benchmark contribuiscono a guidare la comunità degli sviluppatori che usano questi framework. Se questi benchmark non sono accurati si rischia di favorire sistemi con più alta probabilità di errore rispetto ad altri. Lo studio lo trovate qui. Mentre su questo sito sempre del Mit trovate le etichette sbagliate.
Di quali dataset parliamo? Come si legge qui la classifica è stata stilata usando dataset con più di 100.000 citazioni. Quindi Amazon, IMDb, Quick, Draw!, ImageNEt e YouTube. I ricercatori stimano che QuickDraw avesse la più alta percentuale di errori nel suo dataset, al 10,12% delle etichette totali. CIFAR si è classificata seconda, con circa il 5,85% di etichette errate, mentre ImageNet è stata subito dietro, con il 5,83%. E 390.000 errori di etichetta costituiscono circa il 4% del set di dati di Amazon Reviews.
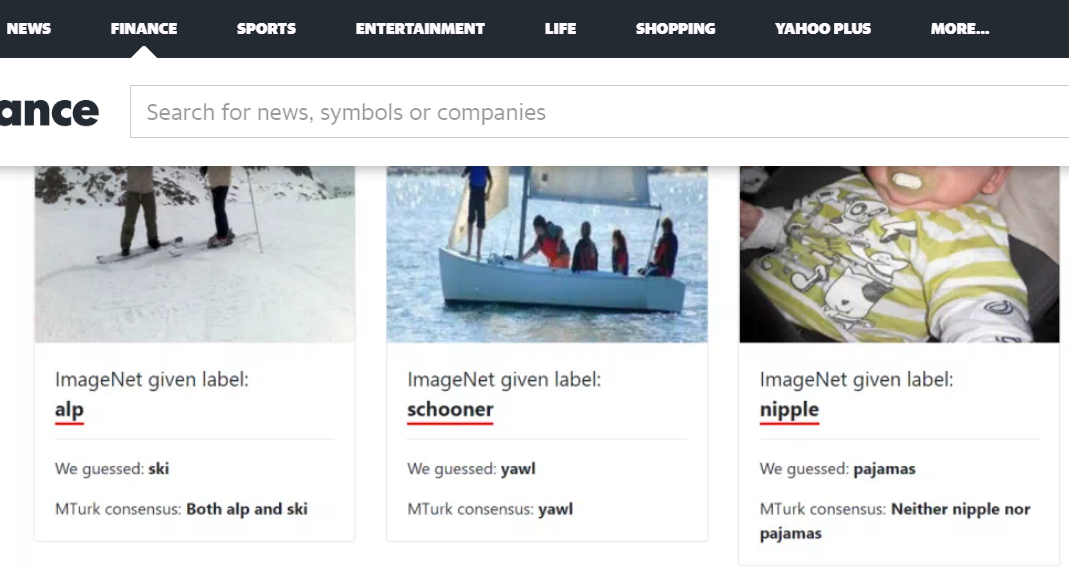
Di che tipo di errori parliamo? Errori sono emersi da problemi come le recensioni dei prodotti Amazon che venivano etichettate erroneamente come positive quando erano effettivamente negative e viceversa. Alcuni degli errori basati sulle immagini derivano dal mescolare specie animali. Altri sono nati dall’errata etichettatura di foto con oggetti meno prominenti. Un esempio particolarmente curioso che è emerso è stato quello di un bambino confuso per un capezzolo.
Attenzione, errori di questo tipo non sono diciamo insoliti. Per affinare gli algoritmi di computer vision per esempio servono immagini, molte immagini, migliaia, milioni di immagini. I dataset aperti svolgono questo compito. Se sono gratuiti e godono di una alimentazione costante meglio ancora. Quali sono le conseguenze: come avviene in statistica se il campione presenta degli errori c’è un effetto a cascata sulle funzioni. Nel caso dell’Ai la quantità di dati aiuta a correggere l’errore ma le dimensioni secondo i ricercatori amplificano anche le possibilità di errore rispetto a sistemi più puliti.
Perché è un problema. “Tradizionalmente, i data science scelgono i framework aperti in base ai test. Occorre quindi più cautela”, hanno scritto i ricercatori. “È fondamentale essere consapevoli della distinzione tra l’accuratezza del test corretta e quella originale.” Sostanzialmente, servirebbe un test sulla qualità dei dataset.
Per promuovere benchmark più accurati, i ricercatori hanno rilasciato una versione pulita di ciascun dataset in cui è stata corretta gran parte degli errori dell’etichetta.
{kind=link}
{kind=link}