di Luigi Curini (in collaborazione con Francesco Periti)
In questi ultimi anni, abbiamo assistito ad una straordinaria crescita di interesse in più discipline (dalle scienze sociali, a quelle statistiche ed informatiche) nei confronti della text analytics e più in generale dell’elaborazione del linguaggio naturale (NLP in inglese: Natural Language Processing), tecniche che mirano a conferire alle macchine la capacità di comprendere il linguaggio dell’uomo sfruttando l’enorme quantità di informazioni espresse verbalmente o per iscritto. Analisi quantitative, incluso il machine learning, sono utilizzate per scopi molteplici in vari domini applicativi, alcuni dei quali sorprendenti, derivati da analisi in realtà sviluppate per tutt’altro.
Tra questi, sta producendo molta dibattito una tipologia di analisi volta a valutare la possibile esistenza di stereotipi e/o cliché che emergono (volontariamente o meno) dalle regolarità del linguaggio utilizzato. Con stereotipi si intendono generalizzazioni relative a gruppi sociali, attraverso un processo di categorizzazione in cui tutte le persone di quel gruppo sociale finiscono per essere racchiuse, senza alcuna differenza tra di loro. Di solito derivano da precedenti esperienze personali o da opinioni diffuse che poi si cristallizzano e vengono condivise, grazie alla loro capacità di semplificare la complessità del mondo per chi le usa. Il problema degli stereotipi è che sono difficili da modificare, e spesso contengono una forte valenza pregiudiziale nei confronti del gruppo in questione. Quante volte abbiamo sentito lo slogan: “italiani pizza, mafia e mandolino?”. Stereotipi di questo tipo trovano anche una rappresentazione implicita nel linguaggio utilizzato nei testi, dove analisi automatiche di moli rilevanti di documenti tendono ad estrarre, a partire da regolarità sintattiche, relazioni tra alcuni termini. Per esempio, in documenti dove la parola madre compare frequentemente nelle vicinanze della parola donna, uno strumento automatico di analisi potrebbe suggerire come parola rappresentante di donna il termine madre, mentre sappiamo bene che non basterebbe probabilmente neanche una intera enciclopedia per descrivere ciascuno di noi, donne o uomini poco importa.
Questo esempio non è casuale. I possibili stereotipi di genere codificati nelle regolarità del linguaggio scritto e parlato sono infatti uno dei temi che sta venendo maggiormente analizzato con le tecniche di NLP. Al momento però, resta inesplorato, almeno per quanto riguarda la situazione italiana, il linguaggio utilizzato dai politici considerando un lungo arco temporale. Una mancanza importante che potrebbe al contrario mostrarci l’evoluzione del linguaggio impiegato da chi siede in Parlamento, ovvero nella sede principe della deliberazione in un contesto democratico, per affrontare le sempre nuove dinamiche, discussioni e vicende che coinvolgono il paese (dall’impatto del ’68 e successiva battaglia dei diritti civili, fina al più recente #metoo, ad esempio).
Per rispondere a questi quesiti, il presente articolo riporta alcuni dei risultati preliminari di una ricerca portata avanti dal Dipartimento di scienze sociali e politiche e dal Dipartimento di informatica dell’Università degli Studi di Milano, che vede coinvolti, oltre agli autori di questo pezzo, anche Fedra Negri, Silvia Decadri, Alfio Ferrara e Stefano Montanelli, su tutti i discorsi parlamentari nella Camera dei Deputati dall’inizio della prima legislatura (nel lontano 1948) ai giorni nostri. Si tratta di una mole davvero ingente di dati che include oltre 1 milione di interventi digitalizzati, effettuati in circa 11.500 sedute dai parlamentari, uomini e donne, che si sono susseguiti nelle 18 legislature. Questi dati testuali, e le parole al loro interno, sono stati analizzati attraverso un processo conosciuto come di word embedding. Tralasciando del tutto la parte tecnica, tale processo si basa fondamentalmente sull’implementazione di due ipotesi. La prima è stata avanzata nel 1957 dal linguista John Rupert Firth, secondo cui “si può comprendere una parola guardando alla compagnia che tiene”. Ovvero, il significato di una parola può essere recuperato guardando alle altre parole che occorrono nelle sue immediate vicinanze, ogni qual volta quest’ultima compare in un testo. La seconda rinvia all’ipotesi della semantica distribuzionale secondo cui parole distinte che condividono largamente l’insieme di parole che sono poste intorno a loro (ovvero parole che occorrono negli stessi contesti lessicali), possono essere riconosciute come simili (o “apparentate”) nel loro significato. Attraverso il processo di word embedding, in particolare, tutte le parole incluse in un insieme di documenti (i discorsi parlamentari alla Camera dei Deputati nel nostro caso) possono essere rappresentate come punti in uno spazio multidimensionale in cui parole semanticamente simili hanno una rappresentazione vicina nello spazio. Per fare un esempio del tutto ipotetico, la parola PlayStation potrebbe risultare prossima geometricamente a Xbox, o almeno decisamente più vicina a quest’ultima rispetto alla parola bicicletta. Allo stesso modo, la parola bicicletta potrebbe risultare prossima alla parola mountain-bike, piuttosto che alla parola Italia che a sua volta sarà prossima alle parole Roma e Francia e così via. Un aspetto interessante da sottolineare è che il word embedding permette al computer di recuperare queste preziose informazioni semplicemente dall’implementazione delle due ipotesi precedenti, senza essere stato istruito in alcun modo da un ricercatore umano sul significato delle parole in questione.
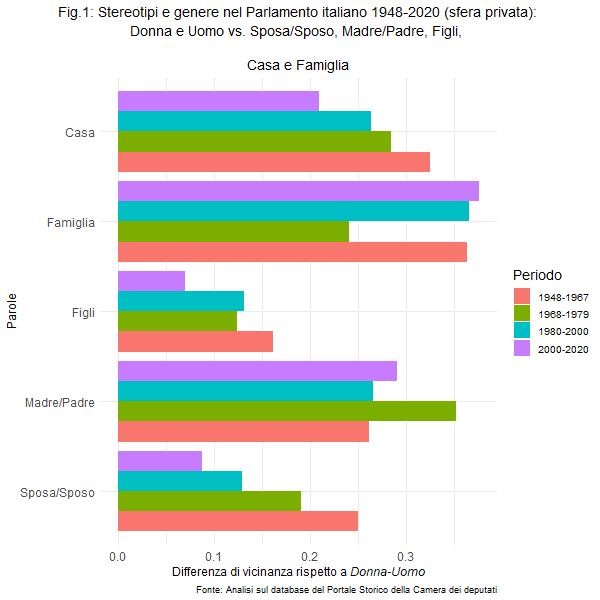
Cosa ci dicono dunque i risultati per quanto riguardo gli stereotipi di genere nel parlamento italiano? Ci siamo focalizzati in particolare su 4 distinti periodi storici: quello che va dal 1948 al 1967, quello che parte dal ’68 per finire nel 1979, e i due successivi ventenni: quello dagli anni 80 a inizio 2000, e gli ultimi 20 anni della storia politica italiana. Inoltre, abbiamo distinto due limitati insiemi di parole. Quelle più legate alla sfera privata e quelle meno. In entrambi i casi abbiamo seguito la medesima procedura. Prendiamo il caso della sfera privata. Abbiamo calcolato da un lato la forza dell’associazione geometrica tra la parola donna e le parole madre, sposa, figli, famiglia e casa (dove un valore più elevato indica una associazione più accentuata); dall’altro la stessa associazione geometrica ma considerando questa volta la parola uomo (e ovviamente sostituendo madre con padre e sposa con sposo). Abbiamo poi sottratto il valore che risulta per la donna con quello che risulta per l’uomo. In questo modo, un valore positivo implica che una data parola (ad esempio famiglia) risulta associata maggiormente alla parola donna che alla parola uomo, mentre un valore negativo implica l’opposto.
La figura 1 mostra i risultati a questo riguardo. Come si può osservare, tutti i valori risultano largamente positivi, ovvero le parole considerate (madre/padre, figli, sposa/sposo, famiglia e casa) appaiono nel corso dei periodi storici da noi analizzati sempre più associate al termine donna che uomo. Questo è vero in primis per il termine famiglia, seguito dallo status genitoriale. Insomma lo stereotipo donna/sposa/madre/figli/famiglia/casa appare in modo non banale nel linguaggio del Parlamento italiano, non necessariamente (o non solo) perché i deputati sostengano questi stereotipi, è bene sottolinearlo, ma anche perché riflettono quello che è presente nel linguaggio fuori dal Parlamento.
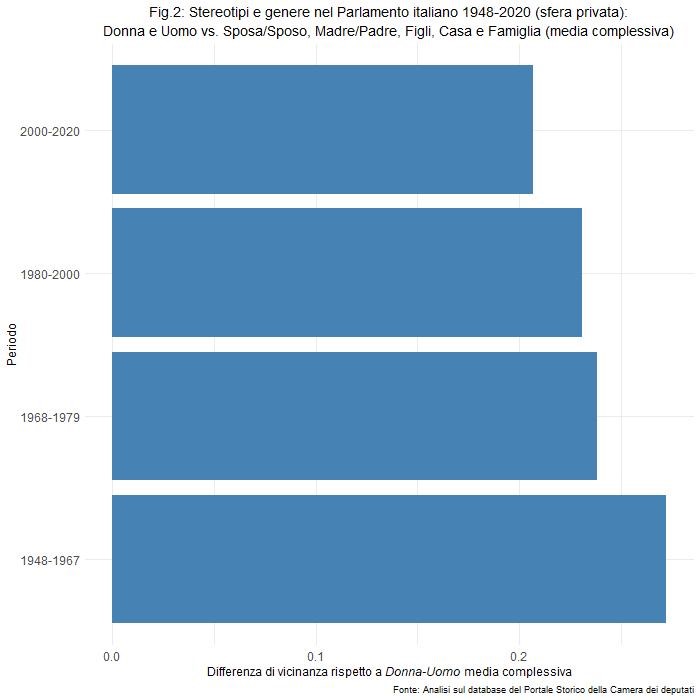
E per quanto riguardo la sua evoluzione temporale complessiva? Qua le cose vanno meglio. Lo si può osservare nella figura 2, dove riportiamo la media complessiva per periodo storico dei valori delle parole presenti nella precedente figura. Come si può vedere, il dato “stereotipale” maggiore si ha nei primi 30 anni della repubblica italiana. Il periodo successivo al ‘68 registra invece un primo lieve declino, che continua negli anni 80, per registrare il dato sensibilmente più basso negli ultimi 20 anni. Insomma, un trend che fa ben sperare.
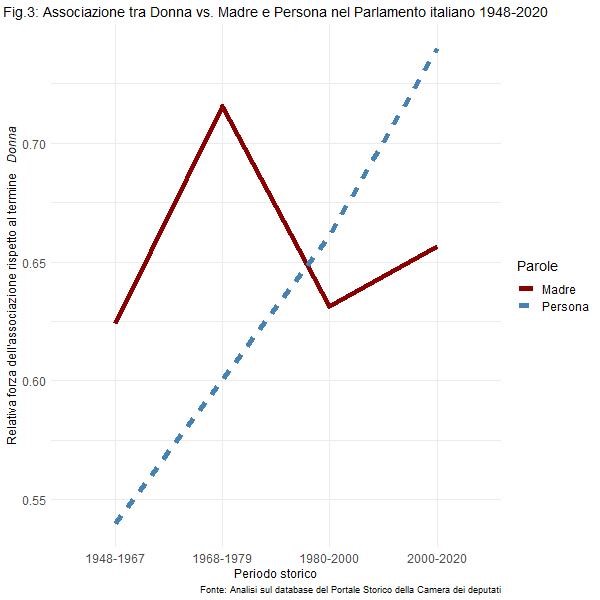
Questo può essere anche apprezzato nella figura 3, dove la forza dell’associazione tra la diade donna-madre e la diade donna-persona, è mostrata, in evoluzione, per periodo storico. Come si può osservare, il termine persona soppianta quello di madre come termine più associato a quello di donna negli ultimi decenni.
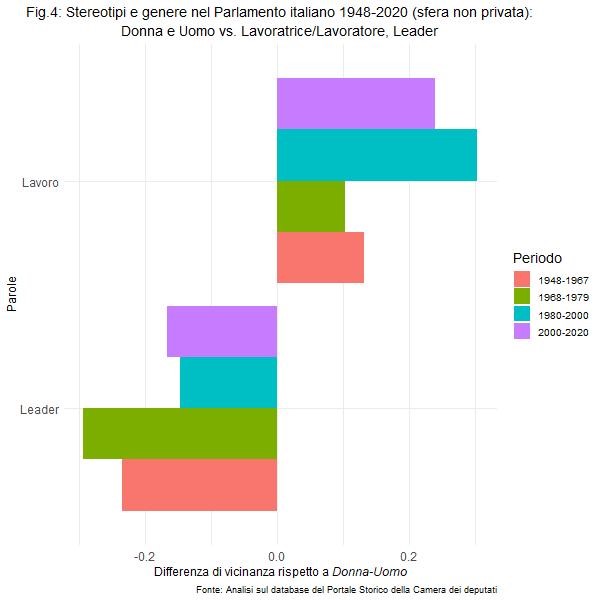
Un cauto ottimismo che possiamo riscontrare, almeno in parte, anche quando ci focalizziamo su altre parole non propriamente legate alla sfera privata. Ad esempio, guardando la figura 4, possiamo vedere che il termine lavoratrice risulta maggiormente associato a donna, di quanto lo sia lavoratore per l’uomo, in misura decisamente maggiore negli ultimi 40 anni rispetto ai primi 30 anni della repubblica italiana. Segno di una crescente sensibilizzazione al tema del lavoro femminile a livello politico.
Dobbiamo allora rallegrarci? In parte sì (almeno in chiave temporale), ma alcuni stereotipi sembrano mantenere una loro validità. E vengono ben rappresentati dalla parola leader. In questo caso, la vicinanza con il termine uomo è netta e ci suggerisce che la maggior parte dei leader (politici e non, italiani e non), citati in parlamento, sono uomini, nonostante la presenza di grandi leader internazionali donna nel corso degli anni come la Thatcher e la Merkel.
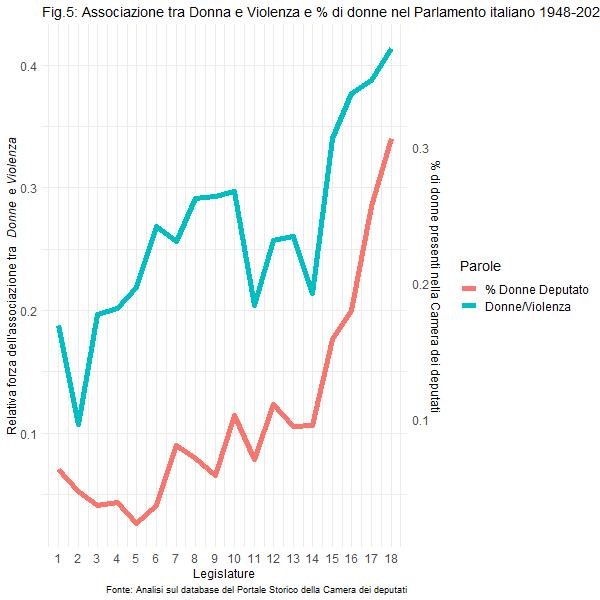
Insomma, questa analisi preliminare sembra mostrare (in alcuni tratti, e seppure con ancora alcune aree grigie) un promettente cambiamento del linguaggio usato in parlamento per affrontare gli stereotipi di genere, che ovviamente rispecchiano anche modifiche profonde (e benvenute) avvenute nella società italiana. Certo, rimane un dubbio, ben rappresentato dall’ultima figura che riportiamo, in questo caso con una cadenza temporale che coinvolge ogni singola legislatura, relativa all’associazione tra i termini donne e violenza. Come si può vedere, tale associazione cresce in modo drammatico nel corso degli anni, a conferma di una crescente attenzione sul tema. Ma questo andamento va di pari passo con l’aumento della presenza delle donne tra i deputati eletti.
Il che fa sorgere un ragionevole dubbio: il miglioramento in termini di stereotipi di genere nel linguaggio utilizzato nel Parlamento italiano che sovente abbiamo osservato nelle nostre figure, è dovuto a parlamentari (uomini) che hanno cambiato il loro registro comunicativo in fatto di genere o è invece più prosaicamente legato al fatto che ad essere cambiati sono stati gli stessi parlamentari (con una maggiore presenza di donne in Parlamento)? Un punto niente affatto banale, che ovviamente merita una particolare attenzione futura.
Data Analysis ospita interventi di ricercatori e docenti universitari e analisi di data journalist ed esperti su working paper, articoli scientifici e studi che parlano in modo più o meno diretto alla società e alle politiche data-driven.
Autore: Luigi Curini, professore di scienza politica presso l’Università degli Studi di Milano, e visiting professor presso Waseda University di Tokyo. E’ anche chair dello standing group “Metodi della ricerca per la scienza politica” della Società Italiana di Scienza Politica (SISP). E’ co-editor del SAGE Handbook of Research Methods in Political Science & International Relations (2020).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}