L’intelligenza tra virgolette perché i chatbot non sono intelligenti, almeno per come noi intendiamo questo termine. Non esiste una risposta univoca. Esistono numerosi benchmark e altrettante numerose metodologie per misurare aspetti funzionali anche delle performance dell’intelligenza artificiale generativa.
Se limitiamo il campo ai Large Language Models (LLM) e quindi ai chatbot che rispondono a domande in linguaggio naturale si può analizzare per esempio correttezze e tempi delle risposta. Esitono test che misurano la coerenza e la coesione del testo generato dal modello sono test di generazione di testo automatico.
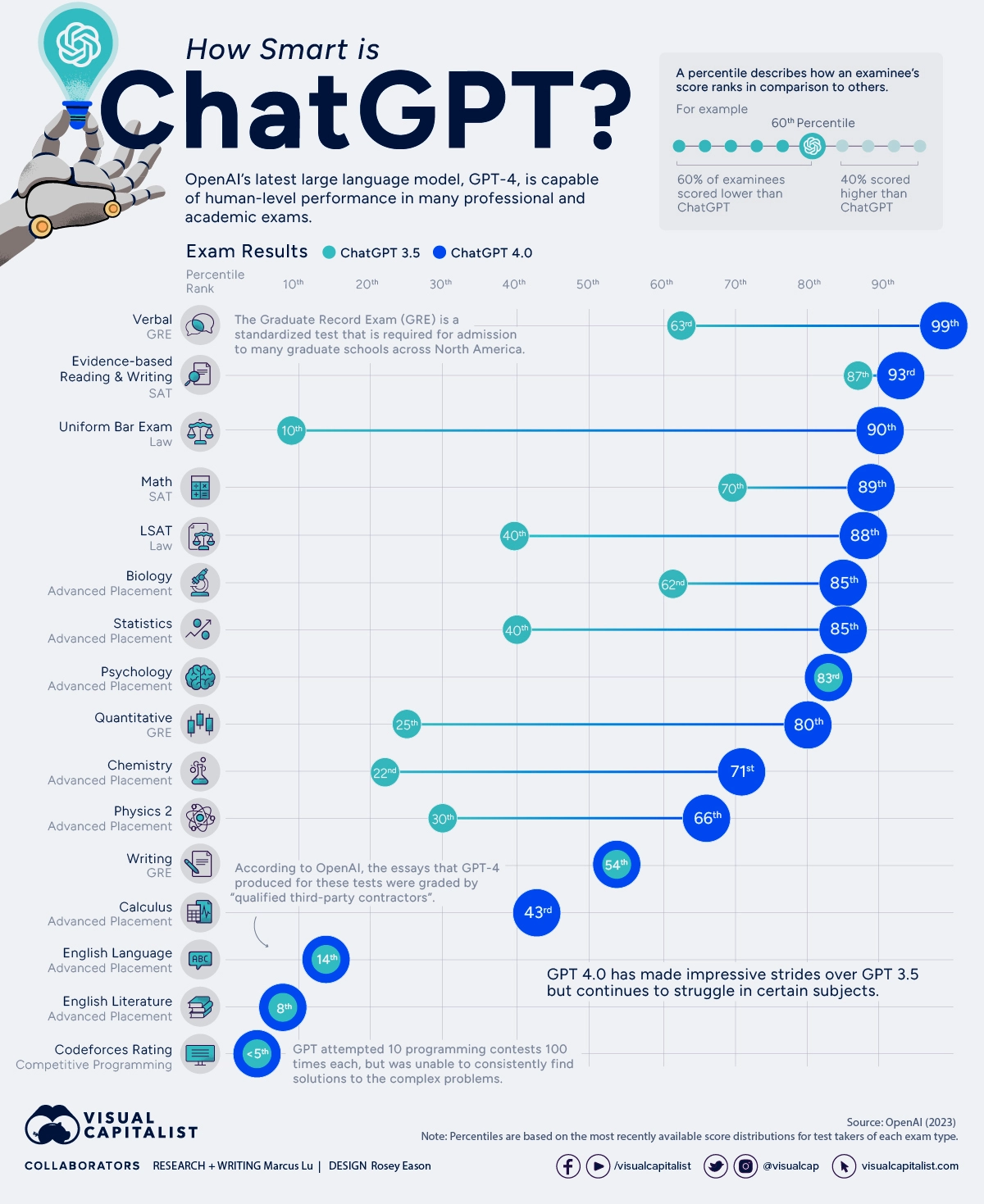
In un rapporto tecnico della fine di marzo OpenAi la stessa società che ha realizzato ChatGpt ha provato a misurare Gpt-4 rispetto a ChatGpt, quindi l’ultima versione rispetto a quella precedente. Sostanzialmente ha simulato l’esecuzione di test di vari esami professionali e accademici. Ciò include i SAT ((Scholastic Assessment Test), l’esame di avvocato e alcuni esami Ap. Questi ultimi esami finali Ap. Questi ultimi test che si fanno nelle scuole superiori americane e in molte scuole superiori canadesi e affrontano le materie negli ultimi anni di liceo con un programma più avanzato (Advanced Placements appunto), con esami aggiuntivi rispetto al normale diploma di high school americana. L’esame SAT (Scholastic Assessment Test) invece è un test riconosciuto in tutte le università americane che valuta il livello di conoscenza dello studente in ambito scolastico. Solitamente tutti i college USA richiedono, per gli studenti stranieri e non, il superamento del SAT. In pratica è una sorta di esame di maturità.
Ciòdetto il test a Gpt-4 ha dato i risultati che vedete riassunti in questa infografica di Visual Capitalist.
Il rendimento è stato misurato in percentili , basati sulle distribuzioni dei punteggi più recenti disponibili per i partecipanti al test di ciascun tipo di esame. Il punteggio percentile è un modo per classificare le proprie prestazioni rispetto alle prestazioni degli altri. Ad esempio, se ti sei posizionato nel 60° percentile in un test, significa che hai ottenuto un punteggio superiore al 60% dei partecipanti al test.
Ma quale è quindi la differenza tra Gpt-4 e i suoi fratelli maggiori?
Il Gpt-4 contiene più dati rispetto al Gpt-3 (45 gigabyte di dati di addestramento contro i 17 gigabyte del Gpt-3). Inoltre, il Gpt-4 è in grado di comprendere e interpretare immagini e fotografie, ampliando le potenzialità del modello di linguaggio. Il GPT-4 ha uscite più lunghe rispetto al GPT-3 (più di 25.000 parole contro le 3.000 parole del GPT-3).
Ciòdetto se ChatGPT è l’auto, allora GPT-4 è il motore: una potente tecnologia generale che può essere modellata per una serie di usi diversi. Quindi per rispondere alla domanda sì, Gpt-4 si comporta decisamente meglio dei suoi fratelli maggiori. Può rispondere meglio alle domande di matematica, compie meno errori quando risponde, cioè non risponde sempre a prescindere a volte inventando ed è anche più attento a non essere offensivo.
Per approfondire.
Come si scrive un prompt per Midjourney?
Adobe Firefly, Dall-E2 e Midjourney, scopri le differenze #Datavizandtools
Come riconoscere immagini e testi generati dall’AI? Parte 2 #Datavizandtools
ChatGpt è un buon programmatore, non è un sofware engingeer e neppure uno sviluppatore.
Wikipedia, l’intelligenza collettiva e gli affari #datavizandtools
L’Ai ha cambiato Bing: tutte le novità (finora)Come si misura l'”intelligenza” di Gpt-4?


{kind=link}