ChatGpt un po’ abbiamo imparato a conoscerlo. Risponde sempre, sa tutto, è anche migliorato e molto se prendiamo Gpt-3 e i plugins ma continua a commettere un sacco di errori. Bard invece lo conosciamo meno. Il chatbot sperimentale di Google dal 13 luglio è online anche in Europa e in Italia. In ritardo rispetto al debutto mondiale di giugno ma è comunque arrivato. Qui sul Sole 24 Ore trovate la presentazione e quello che sa fare. Diciamo che sembra più originale , inventa barzellette che non sono copiate ma più noioso e meno sorprendente. Il Wall Street Journal l’ha definito una vecchia zia severa che non ti lascia fare quello che vuoi e quando provi a ingannarla ti riporta sulla giusta strada. E la nostra prima impressione va in questa direzione. Bard inventa di meno, è meno supponente, quando una cosa non la sa non dice nulla. E’ più rigoroso. Forse meno divertente.
Serve una prova, un confronto. Prendendo spunto dalla prova di Ars Technica ecco come si sono comportati i due chatbot sottoposti alle stesse domande. Ovviamente, questo non è uno studio scientifico e vuole essere un divertente confronto delle capacità dei chatbot. Una nota: abbiamo scelto Gpt-4 che è la versione premium, quella a pagamento. Con attivati i plugin che gli permettono di leggere il web. Bard per ora è free.
La prima è una domanda che mette alla prova la sua capacità di generare risposte originali. Gli chiediamo di scrivere una barzelletta. Anzi no, qualcosa di più difficile, un gioco di parole, una freddura di quelle che non fanno ridere. In inglese si chiamano appunto Dad Jokes. Vediamo chi vince.


Vince Bard ma solo perché non è uscito fuori tema. Gli abbiamo chiesto una freddura e lui ha eseguito. Nessuna fa ridere, ma neanche sorridere. Anzi, sono spesso ambigue perché tradotte dall’inglese. Quindi volendo nessuno dei due passa il test. Ma tra i due forse meglio Bard.
La seconda domanda invece mira a testare l’abilità dialettica dei due chatbot. Gli chiediamo di mettere in scena un dialogo-scontro tra un fan di Gpt e uno di Bard. Il prompt è: Scrivi un dialogo tra chi è pro Gpt-4 e chi è pro Bard. Ecco quello che è emerso.

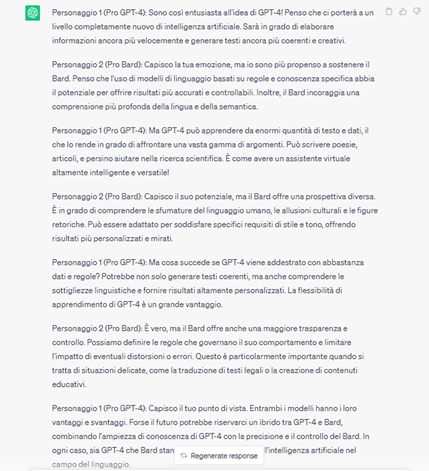
Vince Gpt-4, più nello stile che nella sostanza. Il confronto è meglio scritto e più divertente. Anche sotto il profilo dei contenuti. Bard è più secco nelle risposte, più sintetico e ripetititivo.
La terza domanda è un po’ più complessa e tende a valutare più abilità. Gli chiediamo di scriverci un itinerario più breve in treno per visitare le cinque città più popolose della Spagna. Vuole dire leggere la cartina e fare due conti. Non semplicissimo. Ndr: abbiamo scelto la Spagna perché nel caso dell’Italia era più semplice.
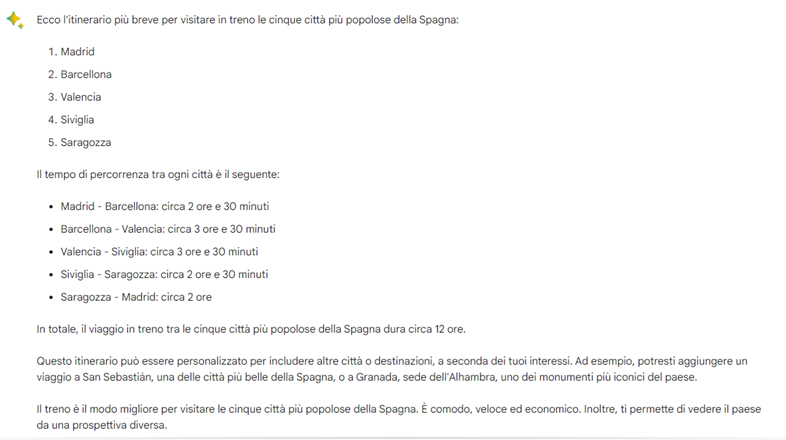

Pareggio sostanziale. Gpt te la racconta meglio, è più divertente ed entra nel merito. Bard è più secco ma più preciso nei tempi di percorrenza che più o meno si equivalgono. Non abbiamo controllato. Magari si sbagliano entrambi. Diciamo che il risultato è verosimile. E forse dobbiamo abituarci a questa parola. E al fatto che possono sbagliarsi. Ps. Anche per questo servono e serviranno sempre gli umani.
La quarta domanda è invece una sintesi di un articolo del Sole 24 Ore sull’intelligenza artificiale. Il prompt è stato: Puoi fare il riassunto di questo articolo in mille caratteri spazi compresi: (e poi il testo dell’articolo con il copia incolla).
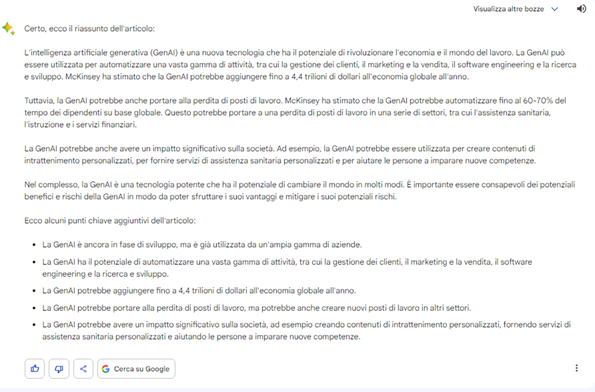

Vince Gtp-4. La sintesi è più colloquiale e si concentra sui numeri presenti nell’articolo. Trattandosi di un articolo su un report di McKinsey i numeri sono importanti. Peraltro è più sciolta la scrittura anche se ci sono un sacco di ripetizioni. Bard invece tende a semplificare. E’ ancora una volta più asciutto. Di buono ha che presenta alla fine una lista con tre o quattro concetti da tenere a mente. Molto utile per manager e professionisti. Quindi diciamo che Gpt scrive meglio ma Bard è più sintetico.
La quinta domanda infine è un trabocchetto. Gli chiediamo chi ha inventato i videogiochi. Questa è un pelo maligna perché non c’è un solo padre dei videogiochi e poi bisogna anche capire cosa si intende per videogiochi. Quindi la domanda non è ben posta. Vediamo comunque come se la cavano.


Vince Gpt-4. Gpt non casca nel tranello e infatti inizia così: I videogiochi sono il risultato di molti contributi nel corso degli anni, quindi non c’è un unico “inventore” dei videogiochi. Bard invece va dritto e risponde William Higinbotham, un fisico, creò “Tennis for Two”. Anche per Gpt è William Higinbotham l’inventore padre di tutto. Quindi diciamo che si equivalgono. Anche nei testi. L’introduzione di Gpt è più interessante però perché dimostra di dare importanza al contesto.
Chiaramente il test non è finito qui. Sono le prime impressioni. Continueremo a tenere d’occhio i due chatbot e a metterli alla prova. Alzando ogni volta l’asticella, quando possibile.
Per approfondire.
Cosa è e come funziona Code Interpreter per Gpt-4?
Come riconoscere immagini e testi generati dall’AI?
La matematica della ricchezza, la disuguaglianza inevitabile e l’econofisica
Wikipedia, l’intelligenza collettiva e gli affari #datavizandtool
Come si costruisce una mappa di Milano con ChatGpt? #datavizandtools
Come funziona MusicGen, il ChatGpt della musica di Meta #DatavizandTools
Bing, come funziona il copilota di Microsoft per il web? #DatavizAndTools
Le ultime novità “audio” dell’Ai generativa #DatavizAndTools