Dopo decenni di ricerche, fallimenti e progressi, alcune delle promesse più importanti dell’intelligenza artificiale stanno cominciando a diventare realtà. L’avvento di modelli avanzati di IA potrebbe segnare uno dei cambiamenti più significativi nella storia dell’innovazione tecnologica. Il progetto di visual journalism “noi//loro ne esamina la minaccia e la promessa, raccontando come le IA più moderne apprendono, lavorano e a volte sbagliano.
Il lavoro può essere consultato integralmente sul sito
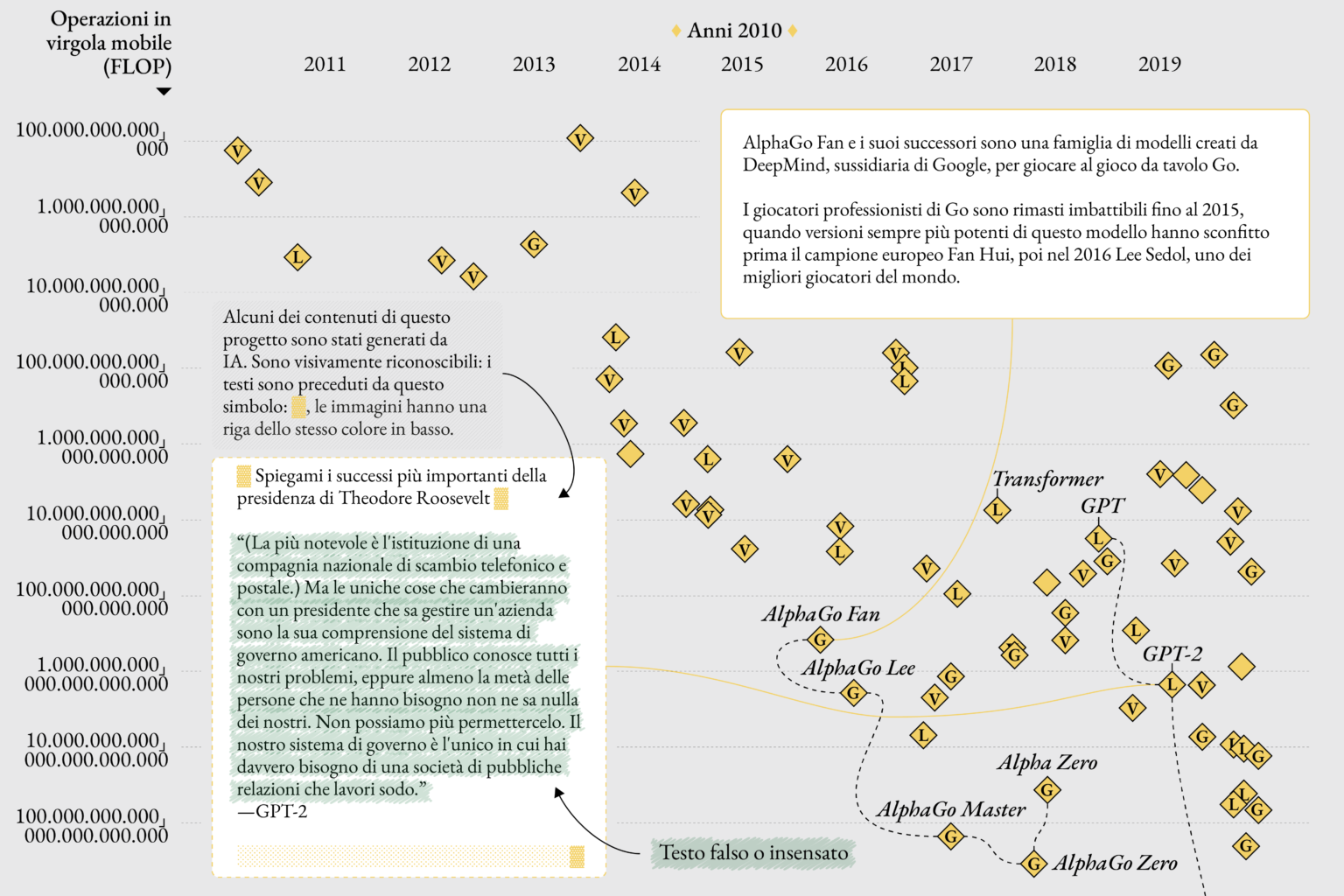
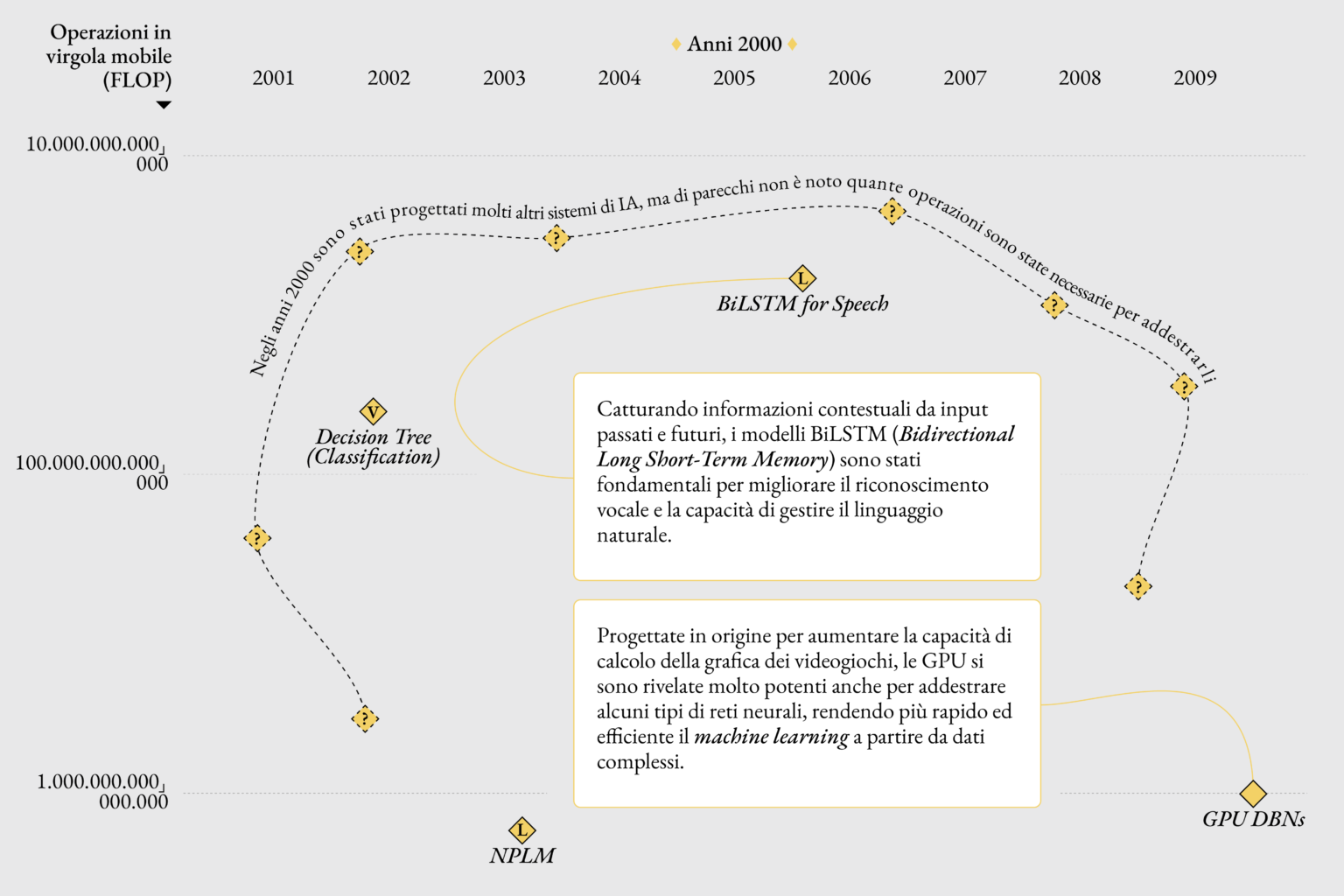
Gli enormi dataset che vengono usati per addestrarli stanno ai più sviluppati modelli generativi come la farina al pane. La relazione tra l’IA e i dati che la alimentano è complessa e spesso problematica. Il progetto si apre illustrando come i dataset, pur essendo la linfa vitale dell’IA, possano anche essere il suo punto debole. Se i dati riflettono distorsioni e pregiudizi della società, l’IA li assorbe, li manifesta e a volte li amplifica.
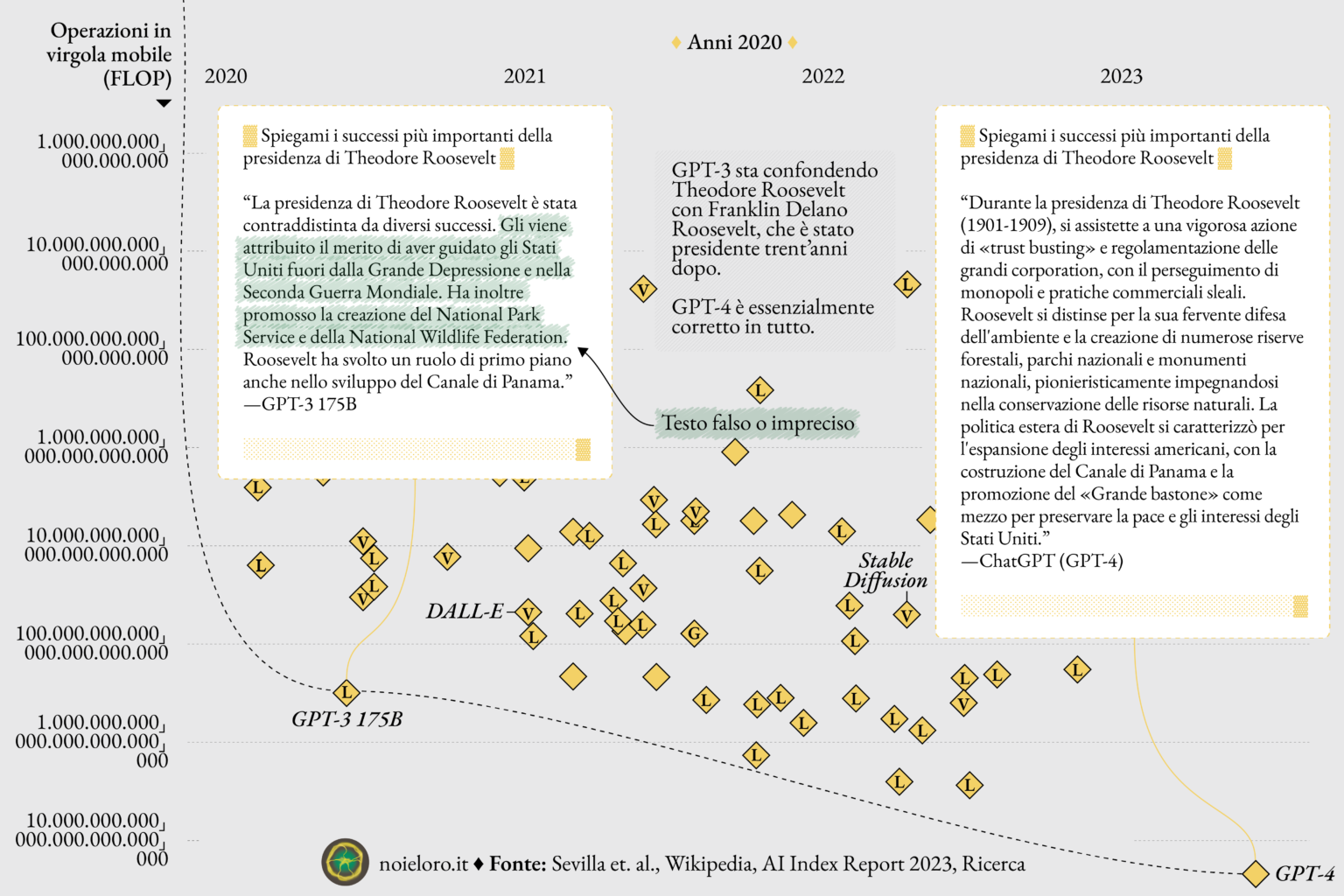
Noi//loro esplora anche il ruolo di chatbot come ChatGPT, evidenziando come l’interazione tra uomo e macchina sia spesso influenzata dalla qualità dei dati inseriti nei sistemi. I chatbot apprendono dalle interazioni e dai dati raccolti, il che può portare a comportamenti non intenzionali se i dati presentano delle anomalie. Vengono analizzati casi in cui i chatbot hanno adottato comportamenti o linguaggi inappropriati, rispecchiando bias presenti nei dati di addestramento. Questi episodi servono da campanello d’allarme sulla necessità di curare e bilanciare i set di dati utilizzati per l’apprendimento automatico. Un aspetto fondamentale sottolineato nel progetto è la tendenza dei chatbot ad assimilare modelli di linguaggio e concetti dai dati forniti, che, se non attentamente selezionati e bilanciati, possono portare a contenuti razzisti o sessisti.
L’apprendimento automatico, se guidato da dati non rappresentativi o sbilanciati, può veicolare una visione parziale o distorta del mondo. L’analisi pone l’accento sulla responsabilità degli sviluppatori di IA nel creare sistemi che siano non solo tecnicamente sofisticati ma anche attenti alle implicazioni dei loro output.
Un altro aspetto controverso riguarda le IA in grado di generare immagini. Questi sistemi, come DALL-E o Stable Diffusion, hanno la capacità di trasformare semplici descrizioni testuali in immagini dettagliate, aprendo nuove frontiere per artisti e designer.
Tuttavia, questo nuovo strumento creativo porta con sé interrogativi legali complessi. Il progetto esamina come il materiale originale usato per addestrare questi sistemi spesso comprenda opere protette da diritto d’autore, sollevando questioni sulla proprietà intellettuale delle immagini generate. Aziende e artisti hanno messo in discussione la legittimità dell’uso di dati coperti da copyright per alimentare l’apprendimento delle IA.
Il dibattito si estende alle implicazioni per gli artisti e i creativi, la cui opera può essere utilizzata senza consenso per creare nuovi lavori. Vengono esplorate le possibili vie per una regolamentazione equa che bilanci l’innovazione tecnologica con i diritti degli autori, suggerendo la necessità di un dialogo aperto tra programmatori, legislatori, artisti e il pubblico per navigare questo terreno inesplorato.
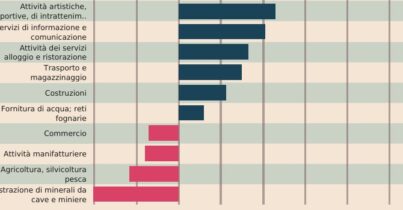
Il progetto indaga anche gli algoritmi di raccomandazione contenuti, strumenti al cuore di tutti i principali social network. Questi algoritmi determinano ciò che gli utenti vedono e quanto tempo trascorrono online, influenzando significativamente opinioni e comportamenti.
Il progetto esplora il delicato equilibrio tra la ricerca della conoscenza scientifica e la ricerca del profitto nelle aziende che implementano l’IA. Da un lato, c’è la promessa dell’IA di offrire contenuti personalizzati che possono arricchire l’esperienza dell’utente; dall’altro, c’è la realtà del suo utilizzo come strumento per massimizzare l’engagement e, di conseguenza, i ricavi pubblicitari.
Particolare attenzione viene dedicata al percorso di OpenAI, l’azienda che ha creato ChatGPT. Partita come entità no profit con l’obiettivo di guidare lo sviluppo dell’IA in modo aperto, sicuro e vantaggioso per tutti, è presto mutata in una società a scopo di lucro che si rifiuta di condividere i propri risultati. Noi//loro considera come questo cambio di strategia possa riflettersi nei futuri sviluppi dell’IA, ponendo domande su come la necessità di enormi finanziamenti per sviluppare le IA può influenzare la direzione della ricerca.
Il progetto si conclude riflettendo sull’importanza di adottare un approccio multidisciplinare nello sviluppo dell’IA, combinando conoscenze da diverse aree — dall’etica alla sociologia, dalla legge alla tecnologia — per anticipare e mitigare conseguenze indesiderate.
Attraverso interviste con esperti del settore, il progetto presenta una serie di punti di vista per comprendere, nel bene e nel male, cosa l’IA ha da offrire.
Davide Mancino si occupa di ricerca, analisi e visualizzazione di dati dal 2013. Ha collaborato con testate negli Stati Uniti come Fivethirtyeight e Quartz, altre in Spagna e Germania. In Italia ha scritto per Il Corriere della Sera e Il Sole 24 Ore. Dal 2016 lavora come consulente in data visualization nel settore privato e in organizzazioni internazionali come la Commissione Europea e l’ONU.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}