Google Research insieme al Weizmann Institute of Science e all’Università di Tel Aviv, ha sviluppato un nuovo modello di intelligenza artificiale per la creazione di video a partire da foto e istruzioni testuali. Si chiama Lumiere, un chiaro omaggio ai fratelli francesi inventori della macchina da presa e del proiettore cinematografico. La novità di Lumiere IA, dal punto di vista tecnologico, è nella qualità con cui il software riesce a ricreare lo spostamento dei soggetti all’interno del filmato. Programmi come Stable Diffusion spesso mostrano imperfezioni dovute alla difficoltà di mantenere una certa coerenza nel rendere animate immagini statiche.
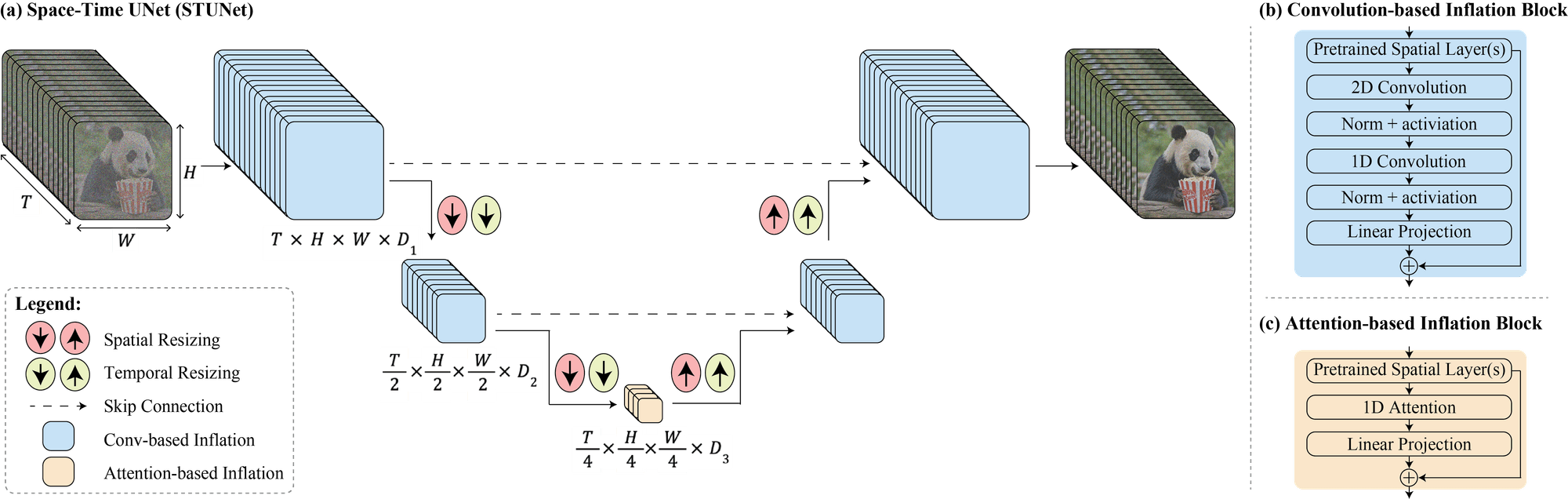
Il nuovo modello di generazione di video IA fa uso del diffusion model Space-Time-U-Net (STUNe), che come si evince dal nome risulta in grado di comprendere dove si trovano gli elementi nello “spazio”, potendoli dunque muovere con l’avanzare del video, il più possibile in modo realistico.
In pratica l’intelligenza artificiale promette di generare il video in un singolo processo, anziché dover lavorare sulle singole immagini fisse. Spesso i soggetti dei video generati con l’Ai sembrano deformarsi da un frame all’altro. Il motivo è che per produrre l’interno video devono generare dei video che stanno “in mezzo” a frame chiave di cui hanno l’immagine. Spesso questi frame generati sono deformati e danno origini a immagini imprecise o “storte”. Google AI ha introdotto un’architettura chiamata Space-Time U-Net che genera l’intera durata temporale del video in un unico passaggio.
Si tratta quindi di un passo in avanti non di poco conto per il mondo IA, come si apprende anche dall’apposito paper pubblicato su arXiv.
Un esempio è quando inseriamo in Lumiere la foto di un peluche chiedendo al programma di farlo camminare da un punto A al punto B. Creando un’unica sequenza spazio-temporale, l’IA genera un filmato in cui ogni attività è strettamente legata l’un l’altra, con sintonia maggiore. Il modello video di Lumiere è stato addestrato su un set di dati di 30 milioni di video, insieme alle relative didascalie di testo. Al momento non è un software aperto al pubblico ma solo un progetto sperimentale di ricerca.
Per approfondire.
Per approfondire.
Microsoft Copilot ora è su tutti gli smartphone. #DatavizAndTools
Come funzionano Nightshade e Glaze? #DatavizAndTools
Fotoritocco, come funzionano Abobe Photoshop Elements e Premiere? #DatavizAndTools
Ecco come funziona Q il nuovo chatbot di AWS? #DatavizAndTools
Ecco come funziona Microsoft 365 Copilot, l’AI generativa entra nelle app di Office
Ecco come funziona GraphCast il nuovo modello per le previsioni meteorologiche globali di DeepMind
Cosa è e come funziona Code Interpreter per Gpt-4?
Come riconoscere immagini e testi generati dall’AI?
La matematica della ricchezza, la disuguaglianza inevitabile e l’econofisica
Wikipedia, l’intelligenza collettiva e gli affari #datavizandtool
Come si costruisce una mappa di Milano con ChatGpt? #datavizandtools
Come funziona MusicGen, il ChatGpt della musica di Meta #DatavizandTools
Bing, come funziona il copilota di Microsoft per il web? #DatavizAndTools
Le ultime novità “audio” dell’Ai generativa #DatavizAndTools
Gpt-4 vs Bard, cinque domande: chi risponde meglio? #howmeasuring
A proposito di mappe, cosa è Overture Maps Foundation? #DatavizAndTools
Ecco le nuove funzionalità di intelligenza artificiale generativa di Photoshop

{kind=link}
{kind=link}