Google che ricordiamo nel 2017 “inventò” i trasformer cioè l’architettura alla base dei ChatGpt e dei Gpt sta lavorando per superare i limiti degli attuali LLM. Un gruppo di suoi ricercatori ha pubblicato un paper scientifico in preprint che illustra le potenzialità di un nuovo modello di Ai chiamato Titan. L’obiettivo è quello di gestire testi lunghi e quindi grandi finestre di contesto senza dimenticare elementi e quindi riducendo gli errori e i consumi energetici. Parliamo quindi dei due limiti fondamentali di un pezzo gigante (quello che genera testo) dell’intelligenza artificiale generativa.
Attention has been the key component for most advances in LLMs, but it can’t scale to long context. Does this mean we need to find an alternative?
Presenting Titans: a new architecture with attention and a meta in-context memory that learns how to memorize at test time. Titans… pic.twitter.com/YY5vqKY9U1
— Ali Behrouz (@behrouz_ali) January 13, 2025
Questi modelli soffrono ancora di limitazioni significative, come l’incapacità di gestire efficacemente informazioni a lungo termine e l’elevato costo computazionale. Spiegamoci meglio. L’architettura dei trasformer che abbiamo conosciuto finora utilizza una tecnica di auto-attenzione che calcola le relazioni sui token e quindi sulle unità del linguaggio per ricombinarle in basse alla domanda. L’efficienza di questo meccanismo che è sotto gli occhi di tutti ha però un limite. Più lunghi sono i testi utilizzati più cresce il costo computazionale e quindi energetico e più aumenta i pericolo di dimenticarsi pezzi e quindi ripondere in modo non preciso inventando di sana pianta o aggiungendo informazioni che non c’entrano niente.
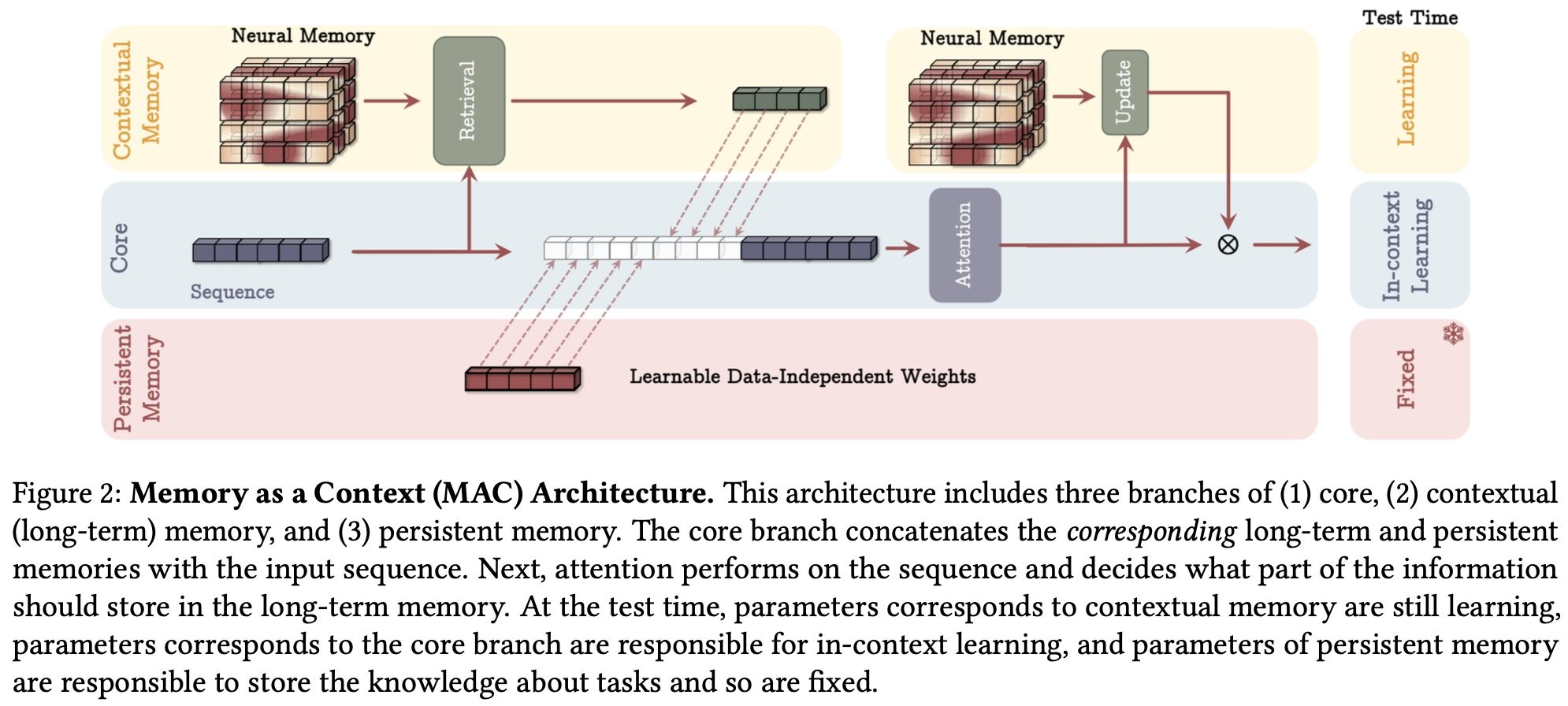
A differenza degli LLM convenzionali, Titan si basa su un’architettura ibrida che integra una memoria neurale a lungo termine che consente al modello di “ricordare” e richiamare informazioni rilevanti anche dopo milioni di token elaborati. Detto altrimenti Titan imita il funzionamento della memoria umana, e attraverso la “sorpresa” distinguendo tra informazioni rivelanti e dati irrilevanti da dimenticare.
Come funziona
Tecnicamente vengono integrare più componenti. Una memoria a lungo termine progettata per memorizzare informazioni critiche e recuperarle su richiesta, anche dopo aver elaborato enormi quantità di dati. Una persistente che racchiude conoscenze globali sul compito in esame, migliorando la capacità del modello di adattarsi a diversi scenari senza riapprendere da zero. L’architettura offre diverse configurazioni, permettendo di integrare la memoria come parte del contesto (Memory-as-Context), come strato autonomo (Memory-as-Layer), o come sistema di filtraggio intelligente delle informazioni (Memory-as-Gate).
La soluzione adottata: insegnare all’Ai a ricordare quello che è utile
Come scrivono i ricercatore, la nostra memoria a breve termine è molto precisa, ma con una finestra molto limitata (30 secondi). Come facciamo a gestire un contesto più lungo? Utilizziamo altri tipi di sistemi di memoria per immagazzinare le informazioni che potrebbero essere utili. L’idea insomma è quella di dotare l’Ai di un modulo di memoria neurale con la capacità di memorizzare un lungo passato per agire come una memoria a lungo termine, più persistente. Siccome non possono ricordare tutti i dati utilizzati per apprendere viene insegnato al modulo di memoria come/cosa ricordare/dimenticare al momento del test.
Quindi cosa è necessario ricordare per rispondere bene?
Per rispondere i ricercatori si sono ispirati al funzionamento della memoria umana. Il nostro cervello dà priorità agli eventi che violano le aspettative (ovvero che risultano sorprendenti). Tuttavia, un evento potrebbe non sorprenderci costantemente nel corso del tempo, pur rimanendo memorabile. Questo perché il momento iniziale è sufficientemente sorprendente da catturare la nostra attenzione su un arco di tempo prolungato, portando così alla memorizzazione dell’intero periodo. Per per addestrare la nostra memoria a lungo termine utilizziamo lo stesso processo. Per calcolare questa sorpresa Titan analizza il gradiente della funzione di perdita rispetto all’input. Per semplificare se l’evento è inaspettato o significativo viene memorizzato. Titans utilizza meccanismi “basati sulla sorpresa” per archiviare selettivamente i dati essenziali durante l’inferenza, ottenendo una migliore generalizzazione e una riduzione dello sforzo di memoria. Al tempo stesso rimuove i dati non necessari, ottimizzando la capacità di memoria limitata. Come facciamo noi quando ricordiamo.
Quali sono le prestazioni?
Secondo lo studio quindi i Titans sono più efficaci dei Transformers e delle moderne RNN lineari e possono essere scalati efficacemente a una finestra di contesto più grande di 2M, con prestazioni migliori rispetto ai modelli ultra-grandi (ad esempio, GPT4, Llama3-80B). In test su attività di language modeling e commonsense reasoning, Titan ha ottenuto una riduzione significativa della “perplexity”, una metrica chiave che misura la capacità del modello di prevedere correttamente la parola successiva in una sequenza. In particolare, nei cosiddetti test di “needle-in-haystack”, dove il modello deve individuare un’informazione precisa all’interno di lunghi testi distraenti, Titan ha mostrato un’efficacia nettamente superiore.
Cosa accadrà ora?
L’impressione è che i Titans avranno delle applicazioni specifiche. Non andranno a sostituire gli attuali LLM. Ad esempio per applicazioni aziendali come la ricerca documentale, l’analisi contrattuale e il monitoraggio delle normative in evoluzione.
Per approfondire.
Cosa è o3 di OpenAi e come si misura? #DatavizAndTools
Come funziona Canvas la nuova interfaccia per ChatGpt? #DatavizAndTools
Ecco come funziona o1, il modello di OpenAi che “pensa” prima di rispondere
Disponibile ChatGpt per Windows. Ecco cosa cambia #DatavizAndTools
L’informazione, i giornali, i viaggi e il senso della vita. La prova di SearchGpt
SearchGpt sta arrivando. OpenAi sfida Google sui motori di ricerca. Ecco cosa sappiamo finora
Che fine ha fatto SearchGpt, il motore di ricerca di OpenAi?
Cosa è AI Overview? Ecco come sta cambiando il motore di ricerca di Google con Gemini
Cosa è WildChat? Più di un milione di prompt (e risposte) per allenare il vostro chatbot
Come si scrive un prompt per Midjourney?
L’Ai Gen si è convertita all’ideologia “woke”? #PromptAnalysis
Quali caratteristiche deve avere un cantante per vincere Sanremo? Risponde Gpt4


{kind=link}