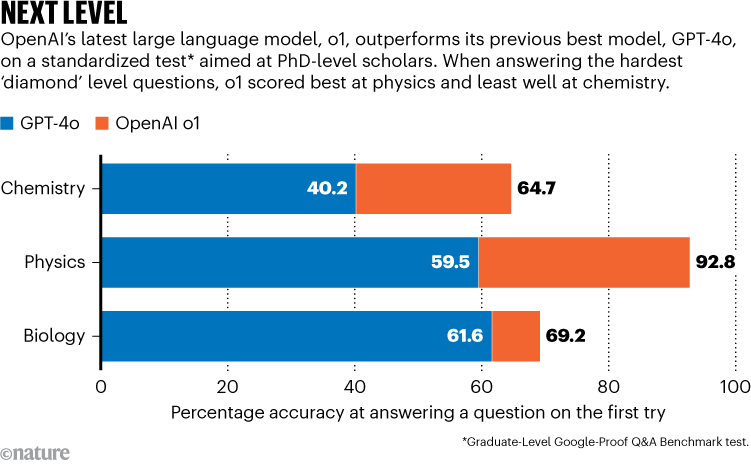
In meno di due anni già si parla di nuova rivoluzione dei chatbot di intelligenza artificiale rispetto alla loro accuratezza sulle materie scientifiche. Per la prima volta il nuovo modello o1 di OpenAI è diventato il primo modello linguistico di grandi dimensioni a battere ricercatori con dottorato di ricerca a un test che prevedeva una serie di domande molto complesse, chiamato Graduate-Level Google-Proof Q&A Benchmark (GPQA).
Da quando a fine 2022 sistemi come OpenAI hanno raggiunto il grande pubblico invadendo le nostre quotidianità, gruppi di scienziati hanno iniziato a testarli a 360 gradi, ognuno per la propria disciplina, con risultati via via sempre migliori, ma fino a oggi il sistema non era riuscito a fare meglio degli scienziati stessi.
Ora, a fine settembre 2024, la rivista Nature ha pubblicato un articolo che rivela che il sistema è riuscito a “battere” un nutrito gruppo di ricercatori con dottorato di ricerca. I ricercatori stessi che hanno contribuito a testare il nuovo modello linguistico di grandi dimensioni di OpenAI, OpenAI o1, affermano che rappresenta un grande passo avanti in termini di utilità dei chatbot per la scienza.
Gli studiosi umani hanno ottenuto un punteggio di poco inferiore al 70% al test, mentre o1 ha ottenuto un punteggio complessivo del 78%, con un punteggio particolarmente alto del 93% in fisica. Ciò è “significativamente più alto rispetto alle prestazioni segnalate come le migliori”, ha dichiarato a Nature David Rein, che faceva parte del team che ha sviluppato il GPQA. Rein lavora presso l’organizzazione non-profit Model Evaluation and Threat Research, con sede a Berkeley che si occupa di valutare i rischi dell’IA.
OpenAI ha anche testato o1 in un esame di qualificazione per le Olimpiadi di Matematica. Il suo precedente miglior modello, GPT-4, aveva risolto correttamente solo il 13% dei problemi, mentre o1 ha ottenuto l’83% di risposte corrette.
“Nel mio campo della fisica quantistica, fornisce risposte significativamente più dettagliate e coerenti” rispetto all’ultimo modello dell’azienda, GPT-4, ha raccontato a Nature Mario Krenn, leader dell’Artificial Scientist Lab presso il prestigioso Max Planck Institute, in Germania. Krenn è stato uno dei pochi scienziati del “red team” che ha testato la versione di anteprima di o1 per OpenAI.
Kyle Kabasares, uno scienziato dei dati presso il Bay Area Environmental Research Institute di Moffett Field, California, ha utilizzato o1 per replicare parte del codice del suo progetto di dottorato che calcolava la massa dei buchi neri. “Ero semplicemente sbalordito”,racconta, notando che o1 ha impiegato circa un’ora per realizzare ciò che a lui ha richiesto molti mesi.
E ancora, Catherine Brownstein, una genetista presso il Boston Children’s Hospital nel Massachusetts, racconta a Nature che l’ospedale sta attualmente testando diversi sistemi di intelligenza artificiale, tra cui o1-preview, per applicazioni come il collegamento dei punti tra le caratteristiche dei pazienti e i geni per le malattie rare. “Questa versione è decisamente più accurata e offre opzioni che non pensavo fossero possibili da un chatbot”.
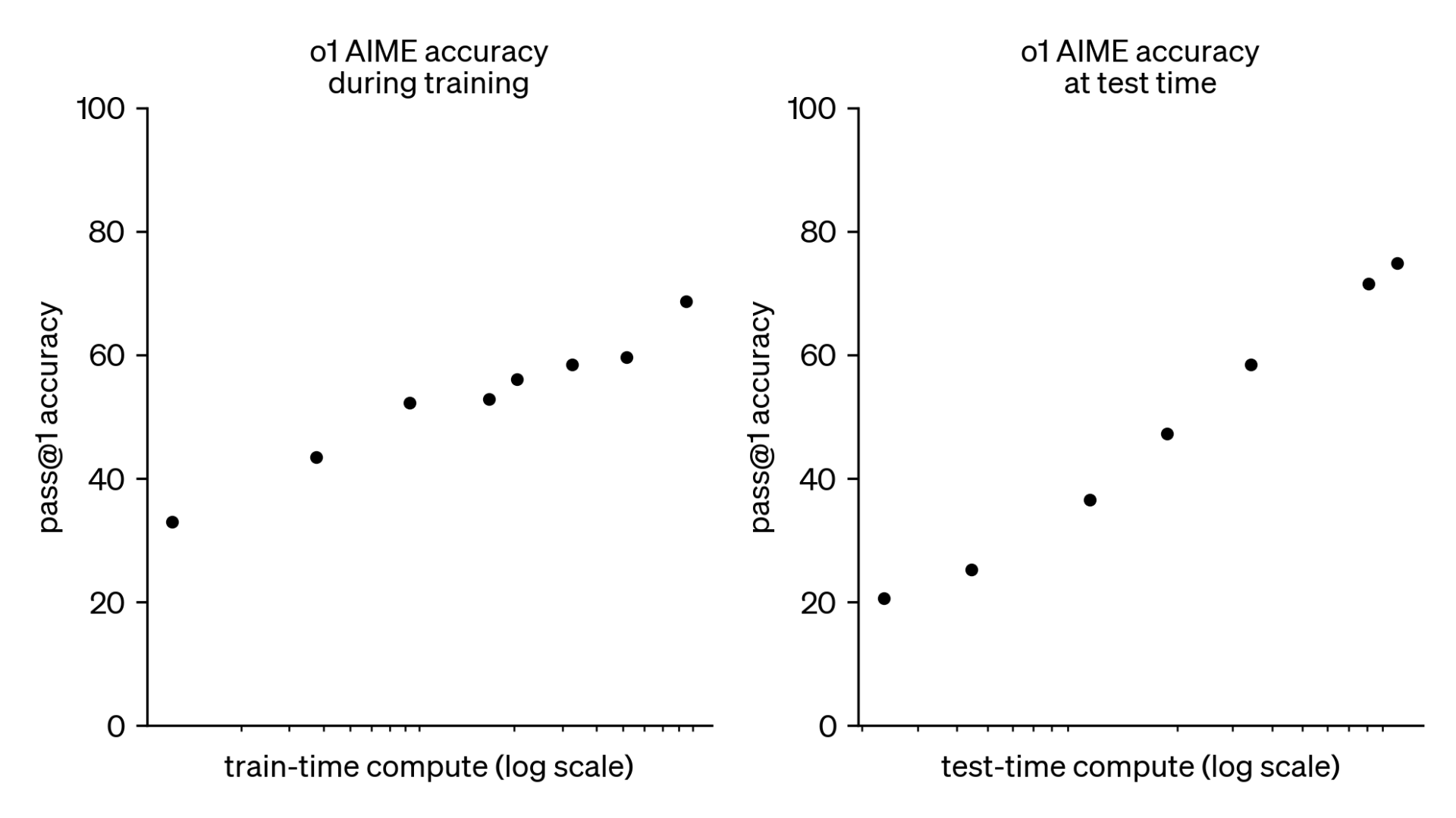
OpenAI o1 funziona utilizzando la logica della catena di pensiero; si parla attraverso una serie di passaggi di ragionamento mentre tenta di risolvere un problema, correggendosi man mano che procede.
La caratteristica distintiva di questo modello di intelligenza artificiale è che ha trascorso più tempo in determinate fasi di apprendimento e “pensa” alle risposte per più tempo, il che lo rende più lento, ma più capace. L’azienda aggiunge che o1 “può ragionare su attività complesse e risolvere problemi più difficili rispetto ai modelli precedenti in scienza, codifica e matematica”. Vedremo. OpenAI non ha comunque rilasciato dettagli su quanti parametri o quanta potenza di calcolo si nascondono dietro il nuovo modello. L’azienda ha deciso infatti di tenere nascosti i dettagli della “catena di pensiero” in parte perché la catena potrebbe contenere errori o “pensieri” socialmente inaccettabili e in parte per proteggere i segreti aziendali relativi al funzionamento del modello. Non sappiamo dunque in realtà come “ragiona” il nuovo OpenAI.
Infine gli scienziati hanno notato che il sistema non fornisce informazioni di sicurezza relative a passaggi pericolosi, come la mancata evidenziazione di pericoli esplosivi o il suggerimento di metodi di contenimento chimico inappropriati, indicando l’inadeguatezza del modello su cui fare affidamento per attività di sicurezza fisica ad alto rischio. Questo nonostante i miglioramenti. In uno dei test di sicurezza più difficili, GPT-4 aveva ottenuto un punteggio di 22 su 100 mentre il nuovo modello o1 ha raggiunto un punteggio di 84 su 100.
In ogni caso, il sistema non è ancora abbastanza perfetto o affidabile da non richiedere un controllo costante. OpenAI segnala di aver ricevuto feedback aneddotici secondo cui i modelli o1 inventano risposte errate, più spesso dei loro predecessori.

Questo problema è ampiamente documentato in letteratura. Solo una settimana prima, il 25 settembre 2024 sempre Nature ha pubblicato un lavoro del team di José Hernández-Orallo del Valencian Research Institute for Artificial Intelligence in Spagna che ha evidenziato che le versioni più raffinate degli LLM sono, come previsto, più accurate, ma su alcune cose sono anche meno affidabili. Tra tutte le risposte non accurate, la frazione di risposte sbagliate è aumentata, proprio perché è meno probabile che i modelli evitino di rispondere alla domanda. Il gruppo ha anche monitorato se la probabilità di errori corrisponde alla percezione umana della difficoltà della domanda e quanto bene le persone riescono a identificare le risposte sbagliate. Risultato: poco. Gli esseri umani non sono mediamente in grado di supervisionare questi modelli. Le persone hanno classificato erroneamente le risposte imprecise come accurate sorprendentemente spesso, all’incirca tra il 10% e il 40% delle volte.
Cosa è Ai Stories? Storie lunghe su fatti, accadimenti e personaggi della rivoluzione Ai Gen.
La altre puntate di Ai Stories
Il rapporto psicologicamente scorretto di Elon Musk con l’intelligenza artificiale #AiStories
Il boom dell’Ai, la legge di Moore e il caso Intel. Il dilemma dei chip #AiStories
Imagen 3 vs Dall-E3: lo scontro educato dei generatori di immagini #AIStories
Per approfondire.
Matematica, catena di pensiero e coding. Cosa ha di diverso o1 di OpenAI?



{kind=link}
{kind=link}